management: Is This The End of Tape?
In past years there was no choice: mainframe sites needed tape. However
improvements in disk and virtual tape technologies today offer ways to run a
tapeless mainframe. So is this the end of tape?
| Tape has always been an essential and integral part of every mainframe
environment. From old reel-to-reel 3420s to the current cartridge-based
units, every mainframe site has relied on tape. For decades it has provided
a cheap, safe, reliable way to store large quantities of backups and archival
data, and to transfer data from site to site. In fact until the last few
years, the only way to receive z/OS software was on tape. |
 |
However tape today is less important than it once was. Disk subsystems offer
more storage for the same money, and in recent years have become almost bulletproof.
Many sites mirror their production disk to remote disaster recovery sites, and
virtual tape servers seamlessly store data intended for tape on disks. So are
tapes now obsolete?
The Decreasing Importance of Tape
Traditionally, tape has been used for four main tasks:
- Backups: of individual databases, application data and entire disks.
- Storing archival data – data that must be retained, but is rarely
used.
- Information transfer – moving data from one site to another.
- Emergencies – backups on tape can be used to restore a system on
a remote site, and standalone utilities residing on tape can be used to recover
a failed system.
However the importance of tapes in these areas isn't as great as it was.
Backups
Most sites still perform regular “full pack” backups of their disk
subsystems as protection in case of a disk failure. However current disk subsystems
use RAID technology and other technical features to the point that disk failures
almost never occur. The “head crash” that in the past would kill
a disk today is not even noticed. Some argue that such full pack backups are
no longer required.
Regular backups of application data, databases and database logs are also made
in case of application or operator failure. With the decreased cost of disk,
these backups could be stored on disk.
For those with a remote disaster recovery (DR) site, the cheapest way to restore
data at that site is to physically transport tape backups (the Pickup Truck
Access Method, or PTAM) and restore from them. However sites with a need for
faster recovery can use mirror facilities available in most disk subsystems
such as IBM PPRC and HDS TrueCopy. These will automatically copy or mirror the
disk contents onto a remote subsystem. The DR site can have up-to-date information
stored on already-running disks, ready to be used in the case of a disaster.
This technology can reduce the downtime of a full production site disaster to
minutes.
Storing Archival Data
The cost per byte of disk has continued to plummet over the past years –
faster than the decreasing cost of tape. Nowhere has this been faster than in
the mainframe arena, where the introduction of RAID systems based on standard
low cost SCSI drives in the 1990s dramatically reduced mainframe disk costs.
This has been matched by reduced environmental and footprint requirements for
disk subsystems (remember the old DASD farms of the 1980s?). So it's now a very
real option to store all archival data on disk.
Information Transfer
If information needed to be
moved from one mainframe site to another, tape used to be the only option. This
could be:
-
To receive software or
software updates.
-
To send dumps or other
diagnostic information to software and hardware suppliers for problem diagnosis.
-
To send information between
companies.
Today this is no longer required.
Software and hardware vendors all provide a way to download software and software
updates, and upload diagnostic information over the internet. Company to company
data transfers can be done simply and securely over the internet using TCPIP
and related tools available for the mainframe.
Emergencies
Tapes are handy in an emergency. Leaving aside their use to restore data from
backups, there are a few utilities that can be IPLed from a tape when z/OS is
down. For example:
- Both IBM DFSMSdss and Innovation FDRABR have a standalone program that
can be IPLed to restore a disk from a backup.
- New Era Software Stand
Alone Environment (SAE) is a utility that can be used to edit datasets
and make other changes when z/OS is down.
- Jan Jaegar has also written a
utility that can edit datasets, but this one is free.
However once installed, these utilities can also be IPLed from disk.
Virtual Tape Servers
Virtual Tape Servers (VTS, sometimes also called Virtual Storage Managers or
VSM) are designed to reduce or eliminate tape mounts. They achieve this by pretending
to be a tape subsystem but storing the data, at least initially, on disk. For
a data write, a VTS would work like this:
- The application writes data to a device. No change required.
- To z/OS this device is a tape. z/OS sends a write operation to this device.
Again, no change required.
- The device is actually a VTS that is pretending to be a tape drive. The
data is written first to the VTS cache and then to disk.
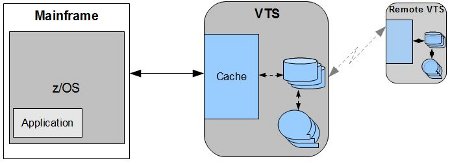
Figure 1: A VTS System
Some VTS subsystems include tape subsystem functionality: either as part of
the unit or as an external tape library. These systems could subsequently migrate
data on the VTS disk to tape, clearing VTS disk space.
The reverse occurs for a read from the VTS:
- The application creates a request for data. No change required.
- To z/OS, this device is a tape. z/OS sends a read operation to this device.
Again, no change required.
- The VTS looks at its internal catalog. If the information is in cache,
it is quickly sent to z/OS. If the information is on disk, it's moved to cache
and sent to z/OS. If it is on tape, then that tape is mounted, the information
copied to disk and cache, and then sent to z/OS.
In short, everyone at the z/OS end think that they are writing and reading
to tape. However they are really writing and reading to a subsystem pretending
to be tape. The advantages of VTS are impressive:
- Because cache and disk are far faster than tape, z/OS tasks accessing tape
can run much faster.
- A VTS can 'pretend' to be many tape drives: up to 256 in most cases. No
more waiting for idle tape drives.
- A VTS can greatly reduce the number of tapes required by intelligently
stacking information on each tape. Of course some tape management software
such as DFSMSrmm and BMC Control-M/Tape can also achieve this.
- VTS have sophisticated management utilities to control the VTS. This allows
users to perform tasks such as creating rules for writing data to tape and
creating tapes for offsite storage.
- VTS have mirror facilities that are similar to disk subsystems. So a production
VTS can have a mirror VTS at a DR site.
Using a VTS isn't the only option to reduce or minimise tape usage. A budget
alternative is to use DFSMSsms to route tape requests to disk, possibly for
later (and more efficient) archival to tape using IBM DFSMShsm or Innovation
FDRABR.
A Route to Tape Removal
So today it is possible to eliminate tape from a mainframe site. This could
be done by:
- Buying enough disk to hold the entire tape library, copy all tape data
to disk, and change the DFSMS configuration (or all JCL) to remove tape reads
and writes.
An alternative would be to implement a VTS to replace all tape drives with
enough internal disk space to hold the entire tape library.
- Implement mirroring of the production disk subsystems and VTS to a DR site.
- Make sure that all standalone utilities are on at least one disk, and their
location well documented.
- Implement electronic file transfer facilities for any transfers between
companies or organisations.
- Order all software electronically.
- Send all dumps and diagnostic information electronically to software vendors.
But is this really a good idea?
The Case for Tape
The big advantages enjoyed by tape have always been cost and reliability. Although
the cost of disk storage is decreasing, the amount of data that needs to be
stored is increasing just as fast. Megabyte for megabyte, tape remains the cheapest
way of storing data – a factor of 10 or so cheaper than disk.
With the push for greener data centres, tape wins again. While spinning disks
are continually consuming power and generating heat, tapes have no such overhead.
Although disk subsystems are very reliable, the possibility of failure is still
present. This can be a media failure, subsystem failure (such as a microcode
error) or environmental failure (such as a machine room flooding, as happened
to Dallas County in the United States a couple of months ago). For essential
application and database backups, tapes are still ideal. Sites without access
to expensive mirroring facilities can use tapes and PTAM to restore systems
at the DR site.
Sites with tape can also use their tape drives for standalone utilities –
useful for worst case situations, such as when the disk holding the utility
is the disk in trouble.
Tape media development has by no means ceased, and tape storage densities continue
to increase (currently up to 1TByte uncompressed per cartridge). In January
IBM, in partnership with Fujifilm, announced a new prototype tape that stores
39 times more data than of today's tape.
But perhaps the biggest thing going for tapes is that they give piece of mind.
Tape is the most reliable way of storing information. It's much harder to accidentally
delete a file on tape, and there's no need to worry about power failures, disk
crashes, microcode problems, or network outages. Data on tape can quietly stay
in a room at the back for decades (up to 30 years for current cartridges).
The Case Against Tape
As anyone who has worked in a data centre knows, tapes require a lot of management.
The more tapes, the more management. Many data centres have tape libraries ranging
into the tens of thousands – and growing quickly.
These tapes quite often move between data centres, and between a data centre
and an off-site location. This is all done manually, with the potential of operator
error. What's more, tapes won't help if no-one knows what is on them. So tape
management software is required, and off-site tapes must have accompanying documentation
showing what is where.
Tapes can break and fail, particularly heavily used tapes. This is usually
managed by:
- Regularly replacing older or higher-used tapes.
- Keeping track of any data errors on tapes.
- Ensuring high-use data remains on disk.
- Keeping backups of important tapes.
It's also much easier to lose a tape. Late last year Zurich announced that
it had lost a backup tape in South Africa holding details of some 51,000 customers
and other parties. This shows that tapes must be secured, and preferably encrypted
to prevent the data landing in the wrong hands.
When migrating to a new tape format, there may be significant work in migrating
legacy tapes to the new format. Although current tape libraries all support
many older formats, it's unlikely that all formats will be supported forever.
Conclusion
Although technically a tapeless mainframe site is possible, it will continue
to be the exception for some time to come. With the increased cost and risk
involved, most sites will stick to the tried-and-true. Tapes are low-tech, and
have far fewer failure points than the alternative tapeless solutions. Having
regular, up-to-date backups and archival data on tapes that are well managed
and regularly checked will give any manager piece of mind. In many mainframe
sites, tape is enjoying a renaissance with data centres under pressure to reduce
costs.
However options to reduce the size of tape libraries and the number of tape
drives will always be appealing. Increased usage of disk for frequently accessed
archival data, together with VTS or other technology to intelligently pack and
manage tapes will be on the wish-list for many mainframe managers.
David Stephens
|
